suppressMessages(library(tidyverse))suppressMessages(library(glue))PRE ="/Users/haekyungim/Library/CloudStorage/Box-Box/LargeFiles/imlab-data/data-Github/web-data"##PRE="/Users/margaretperry/Library/CloudStorage/Box-Box/imlab-data/data-Github/web-data "##PRE="/Users/temi/Library/CloudStorage/Box-Box/imlab-data/data-Github/web-data"## COPY THE DATE AND SLUG fields FROM THE HEADERSLUG="erap2-fine-mapping"## copy the slug from the headerbDATE='2023-03-28'## copy the date from the blog's header hereDATA =glue("{PRE}/{bDATE}-{SLUG}")if(!file.exists(DATA)) system(glue::glue("mkdir {DATA}"))WORK=DATA## move data to DATA#tempodata=("~/Downloads/tempo/gwas_catalog_v1.0.2-associations_e105_r2022-04-07.tsv")#system(glue::glue("cp {tempodata} {DATA}/"))## system(glue("open {DATA}")) ## this will open the folder
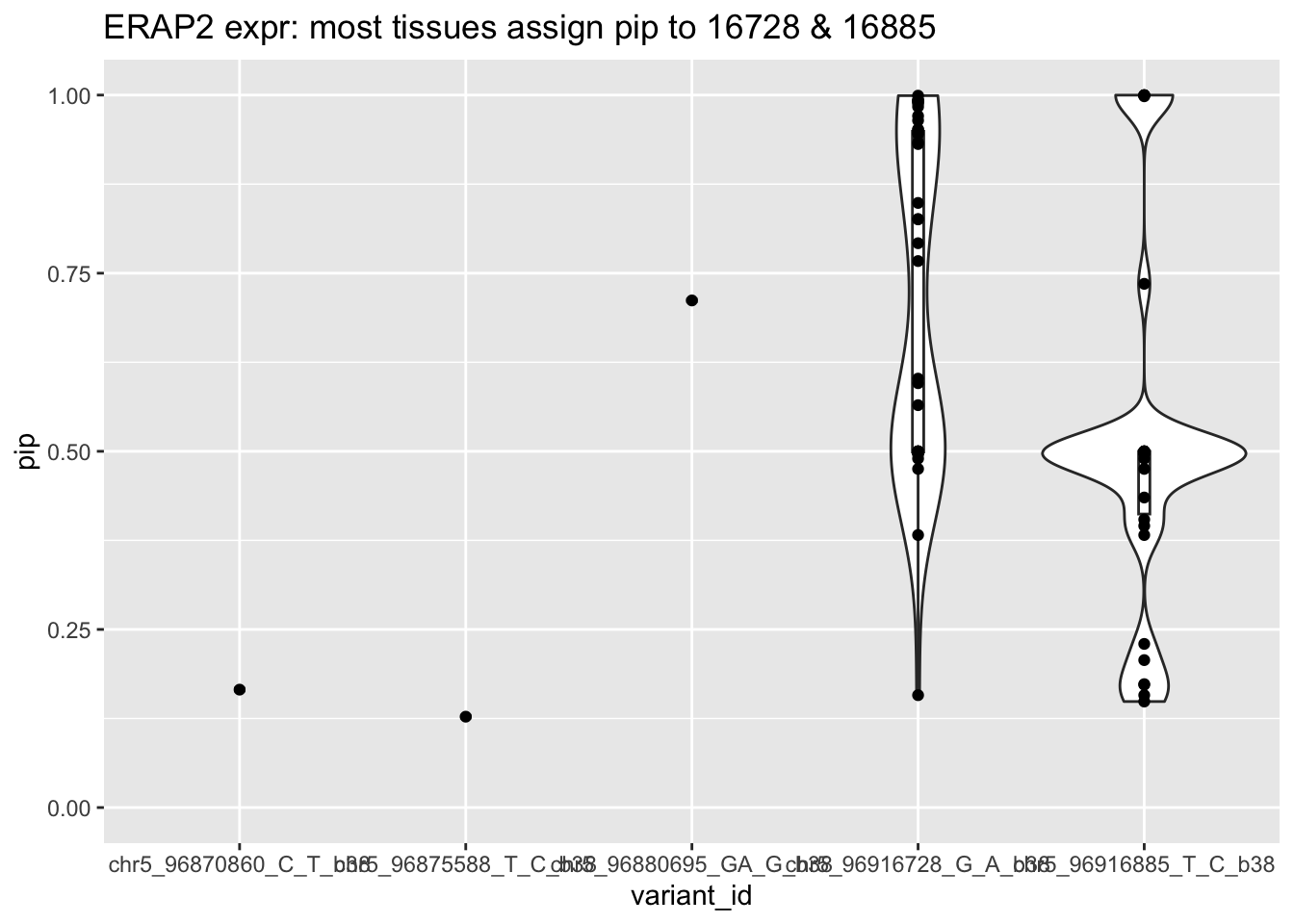
ERAP2 fine-mapping results DAPG
Show the code
## query## SELECT * FROM `gtex-awg-im.GTEx_V8_DAPG.variants_pip_eqtl` where gene like "ENSG00000164308%"erap2 =read_csv(glue("{DATA}/bquxjob_41de6a2f_18728cf1999.csv"))
Rows: 2260 Columns: 7
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (3): tissue, gene, variant_id
dbl (4): rank, pip, log10_abvf, cluster_id
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Show the code
## SELECT * FROM `gtex-awg-im.GTEx_V8_DAPG.variants_pip_sqtl` where variant_id like "chr5_96900192%" order by pip desctauras_snp =read_csv(glue("{DATA}/bquxjob_719c0131_18728db8878.csv"))
Rows: 113 Columns: 7
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (3): tissue, gene_id, variant_id
dbl (4): rank, pip, log10_abvf, cluster_id
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Show the code
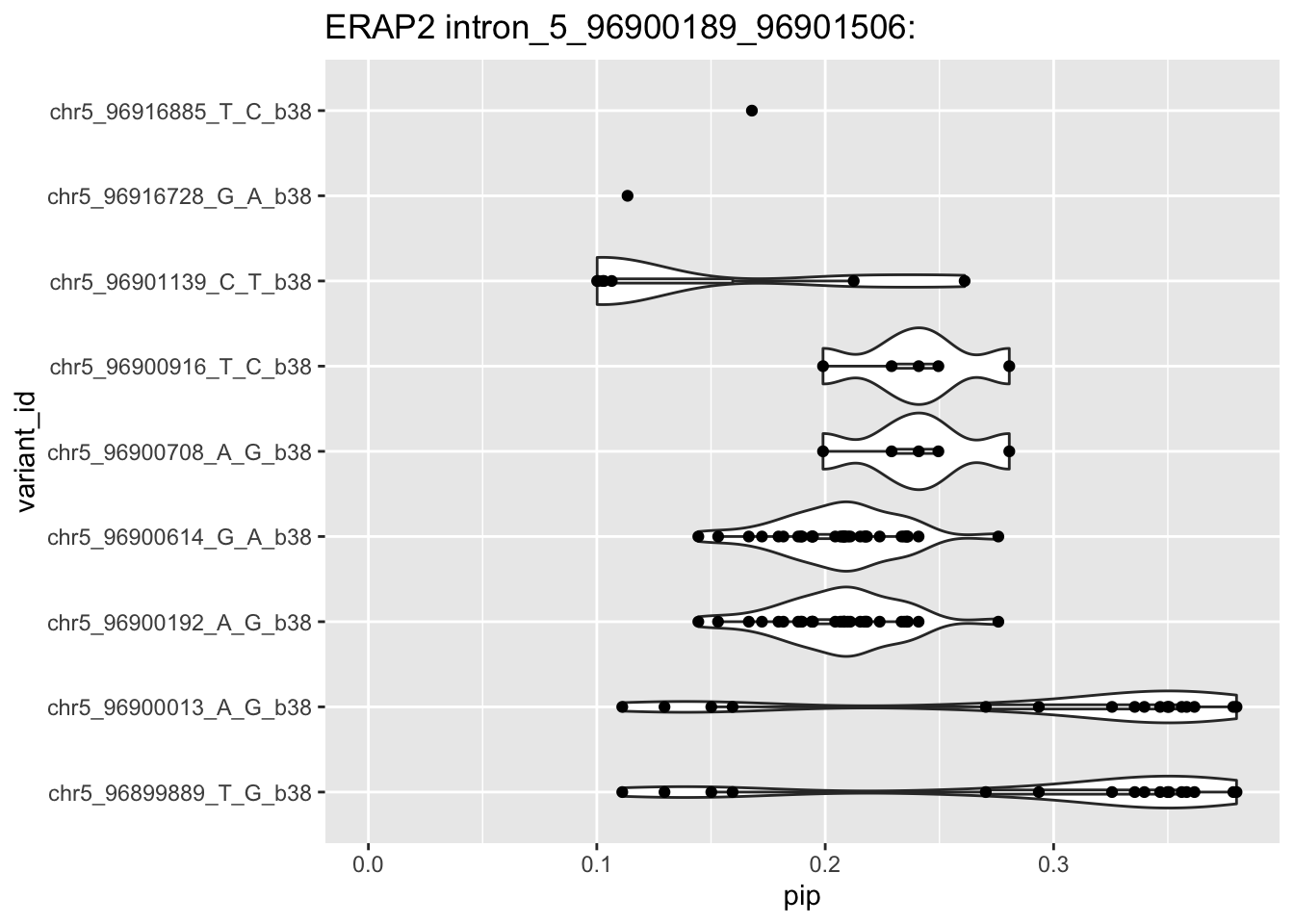
## finemapping for the intron affected by chr5_96900192## SELECT * FROM `gtex-awg-im.GTEx_V8_DAPG.variants_pip_sqtl` where gene_id like "intron_5_96900189_96901506" order by pip descintron =read_csv(glue("{DATA}/bquxjob_41bc6351_18728e4ee94.csv"))
Rows: 2439 Columns: 7
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (3): tissue, gene_id, variant_id
dbl (4): rank, pip, log10_abvf, cluster_id
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Warning: Groups with fewer than two data points have been dropped.
Groups with fewer than two data points have been dropped.
Groups with fewer than two data points have been dropped.
---title: "ERAP2 fine-mapping"author: "Haky Im"date: "2023-03-28"categories: [analysis,how_to]format: html: code-fold: true code-summary: "Show the code"editor_options: chunk_output_type: console---```{r}suppressMessages(library(tidyverse))suppressMessages(library(glue))PRE ="/Users/haekyungim/Library/CloudStorage/Box-Box/LargeFiles/imlab-data/data-Github/web-data"##PRE="/Users/margaretperry/Library/CloudStorage/Box-Box/imlab-data/data-Github/web-data "##PRE="/Users/temi/Library/CloudStorage/Box-Box/imlab-data/data-Github/web-data"## COPY THE DATE AND SLUG fields FROM THE HEADERSLUG="erap2-fine-mapping"## copy the slug from the headerbDATE='2023-03-28'## copy the date from the blog's header hereDATA =glue("{PRE}/{bDATE}-{SLUG}")if(!file.exists(DATA)) system(glue::glue("mkdir {DATA}"))WORK=DATA## move data to DATA#tempodata=("~/Downloads/tempo/gwas_catalog_v1.0.2-associations_e105_r2022-04-07.tsv")#system(glue::glue("cp {tempodata} {DATA}/"))## system(glue("open {DATA}")) ## this will open the folder ```ERAP2 fine-mapping results DAPG```{r}## query## SELECT * FROM `gtex-awg-im.GTEx_V8_DAPG.variants_pip_eqtl` where gene like "ENSG00000164308%"erap2 =read_csv(glue("{DATA}/bquxjob_41de6a2f_18728cf1999.csv"))## SELECT * FROM `gtex-awg-im.GTEx_V8_DAPG.variants_pip_sqtl` where variant_id like "chr5_96900192%" order by pip desctauras_snp =read_csv(glue("{DATA}/bquxjob_719c0131_18728db8878.csv"))## finemapping for the intron affected by chr5_96900192## SELECT * FROM `gtex-awg-im.GTEx_V8_DAPG.variants_pip_sqtl` where gene_id like "intron_5_96900189_96901506" order by pip descintron =read_csv(glue("{DATA}/bquxjob_41bc6351_18728e4ee94.csv"))##intron %>%filter(tissue=="Cells_EBV-transformed_lymphocytes") %>%arrange(desc(pip))## ## erap2 %>% filter(pip>0.1) %>% group_by(variant_id) %>% summarise(sumpip=sum(pip),ntissues=n()) %>% ggplot(aes(variant_id,sumpip)) + geom_bar(stat = "identity") + geom_point() + ggtitle("ERAP2 expr: most tissues assign pip to 16728 & 16885")erap2 %>%filter(pip>0.1) %>%ggplot(aes(variant_id,pip)) +geom_violin() +geom_boxplot(width=0.05,alpha=0.5,outlier.shape =NA) +geom_point() +ggtitle("ERAP2 expr: most tissues assign pip to 16728 & 16885") +ylim(0,NA)print("intron intron_5_96900189_96901506 ")intron %>%filter(pip>0.1) %>%ggplot(aes(variant_id,pip)) +geom_violin() +geom_boxplot(width=0.05,alpha=0.5,outlier.shape =NA) +geom_point() +ggtitle("ERAP2 intron_5_96900189_96901506:") +ylim(0,NA) +coord_flip()#intron %>% filter(pip>0.1) %>% group_by(variant_id) %>% summarise(sumpip=sum(pip),ntissues=n()) %>% ggplot(aes(variant_id,sumpip)) + geom_bar(stat = "identity") + ggtitle("ERAP2 intron_5_96900189_96901506: ") + coord_flip()#ggplot(aes(variant_id,sumpip)) + geom_bar() ```Causal SNP according to the black death paper and others is rs2248374 chr5_96900192